阶段性探索了几种训练方式,玩得很开心…记录一下结果。
先说结论:这东西就图一乐,只适合跑团的时候生成一次性消耗品。要出能用的图,需要非常多的自己改画加+个人想法的加入,还不如直接教自己画画。
测试对象选择小达,因为小达炼起来更难,面具和不对称服装很难教会ai 。相对而言阿钟的西装三件套应该比较好教,到时候直接套用现在的方法就行。
测试方式为让ai分别画圣彼得堡的达达利亚和海边的达达利亚。
训练集大部分是官图,少部分以官图作为素材的l2d。我发现这样反而效果会比塞很多同人好。
探索采用不同方法训练的效果。
不加笔,不筛选,不图生图,就发带错误的原始九宫格,如此进行比较。
途径1
极低的lr,不开注意力优化,bz=1,分辨率1024,10000+步
结果:泛化效果ok,人体出错率最少,空间关系ok,就是长得不太像,并且完全没有学会画面具。
圣彼得堡的达达利亚


海边的达达利亚


途径2
中等lr,开注意力优化,分辨率1024,bz=8,20000+/8步
结果,泛化效果ok,长得还可以,只能说勉强能看出是谁,就是人体爱画错,空间关系可以用炸炉来形容,好在还不黑图。
圣彼得堡的达达利亚


海边的达达利亚

途径3
高lr,开注意力优化,分辨率1024,bz=8,8000+/8步
结果,泛化效果较弱,面具和气质还原最好,就是人体爱画错,空间关系最为 乱套,黑图几率较大。
圣彼得堡的达达利亚

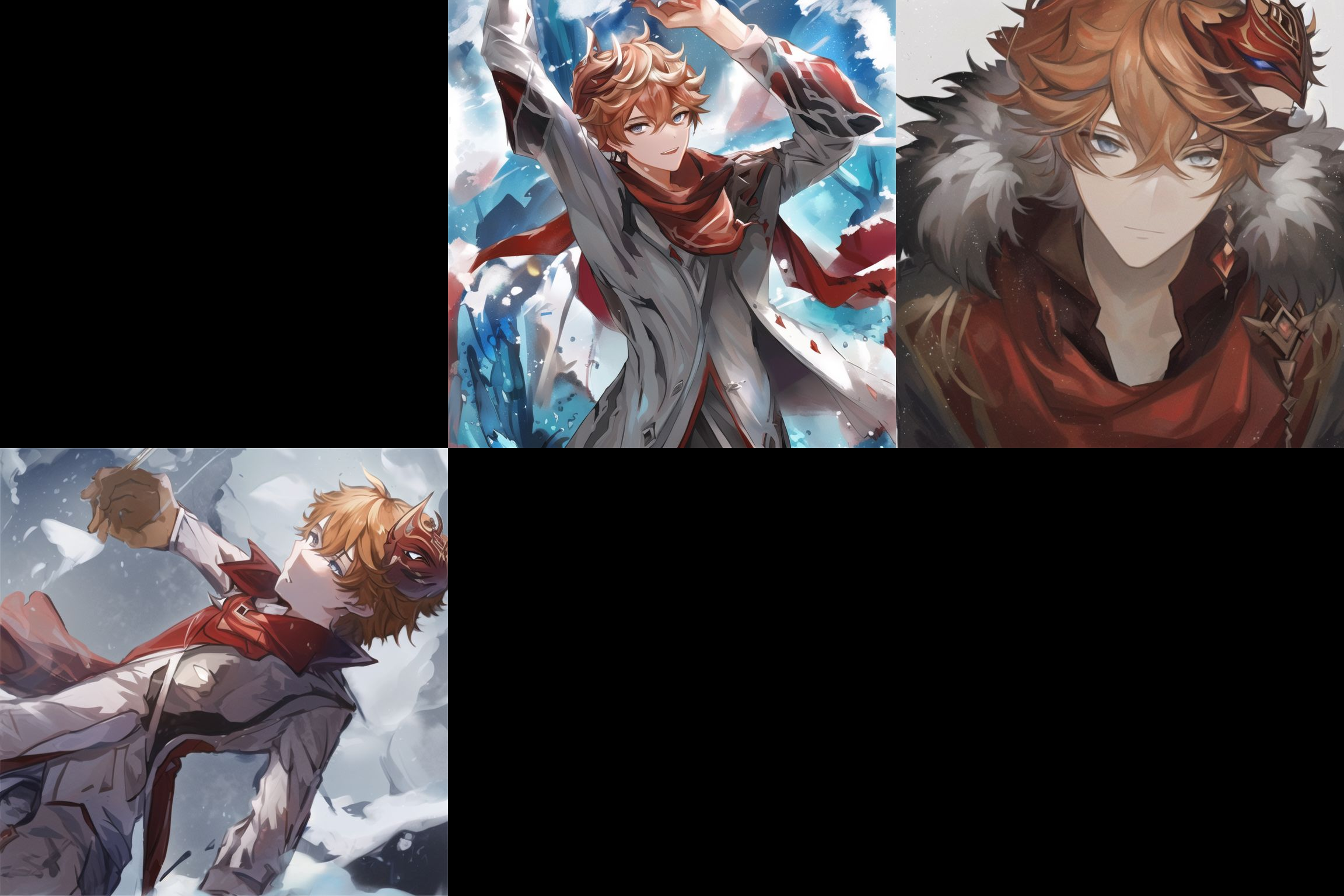
海边的达达利亚


猜测
打开注意力机制可能造成训练结果的空间关系紊乱,虽然可以因此使用更大的bz进行训练。
展望
关掉注意力机制:
- 再现有的40g显存a100上,以768分辨率,bz=3训练
- 下次租80g显存的a100,用1024分辨率,bz=4训练














